TPU VS GPU(日本語版)
はじめに
(この記事の英語版はTPU VS GPU(English Edition)にあります。)
Machine Learning部門の江間見です。ストックマークでは、自然言語処理技術の研究開発を行っています。
昨今、大規模データでニューラルネットワークを訓練し良い結果を得ようとするならば、深層学習モデルの訓練にかかる時間の膨大さに誰もが悩まされたことがあるかと思います。さらに、深層学習モデルはハードウェアのリソースを多く必要とします。
深層学習モデルの学習では、計算の特性上、CPU(Central Processing Unit)より GPU(Graphics Processing Unit)が高速であるため、GPUが推奨されます。しかし、GPU以外の選択肢として、TPU(Tensor Processing Unit)があります。
そこで、本記事では、自然言語処理のタスクで深層学習モデルの学習におけるTPUとGPUを比較していきます。
Processsing Unitの紹介
GPU
GPUは、グラフィック処理や数値計算等で使用される専用メモリを備えた特殊なプロセッサです。GPUは単一処理に特化しており、SIMD(Single Instruction and Multi Data)アーキテクチャ用に設計されています。そのため、GPUは同種の計算を並列に実行(単一の命令で複数のデータを処理)します。
特に深層学習ネットワークでは数百万のパラメータを扱うので、多数の論理コア(演算論理ユニット(ALU)制御ユニットとメモリキャッシュ)を採用しているGPUが重要な役割を果たします。GPUには多数のコアが含まれているため、複数の並列処理を行列計算で高速に計算可能です。
TPU
TPUは、Google社から2016年5月、Google I/O(Google社が毎年開催している開発者向けカンファレンス)で発表されました(すでに同社のデータセンター内で1年以上使用されていたとのことです)。
TPUは、ニューラルネットワークや機械学習のタスクに特化して設計されており、2018年からはサードパーティでも利用可能です。
Google社は、Googleストリートビューのテキスト処理にTPUを使用してストリートビューのデータベース内のすべてのテキストを5日間で発見し、Google Photosでは単一のTPUで1日で1億枚以上の写真を処理できたと発表しています。また、同社の機械学習ベースの検索エンジンアルゴリズム「RankBrain」でも、検索結果を提供するためにTPUを利用しています。
TPUは深層学習タスクを高速化するために設計されたコプロセッサです。図1にTPUブロック図を示します。
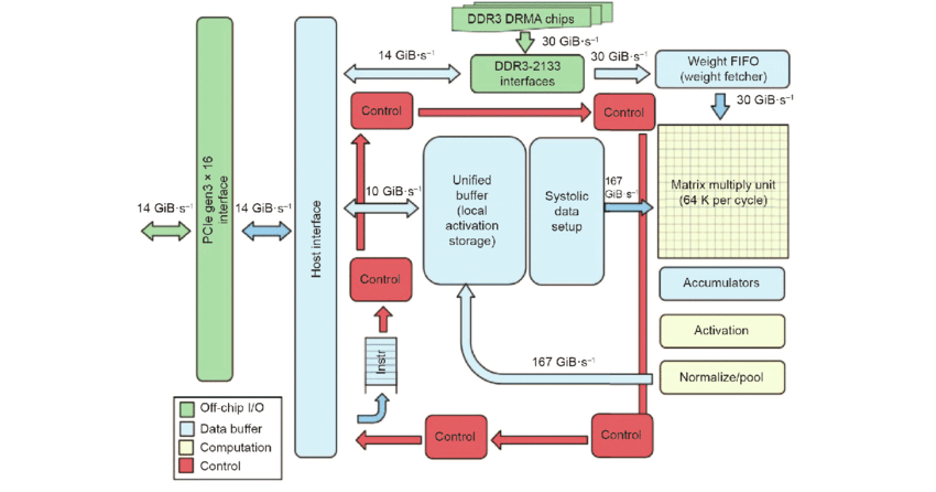
データ転送遅延の可能性を削減するために、TPUはCPUと密接に統合するのではなく、PCIe I/O バス上のコプロセッサとして設計されており、GPU と同様にサーバに接続可能です。
また、ハードウェアの設計とデバッグを簡素化するために、ホストサーバがTPUの命令を自身で実行するのではなく、実行するための命令をTPUへ送信します。つまり、TPUはGPUと比較して、FPU(浮動小数点ユニット)コプロセッサに近い考え方を持っています(Jouppi, et al., 2017)。
図1に示すように、右上隅にある黄色の行列演算ユニットがアーキテクチャの主な計算部分と考えられます。一般的に、CPUは1サイクルあたり数十回の操作を、GPUは1サイクルあたり数万回の操作を、最後にTPUは1サイクルあたり最大128000回の操作を行うことができます。
ハードウェアリソース
比較のために、利用したハードウェアは以下の通りです。
| TPU/GPU | Hardware | Memory |
|---|---|---|
| GPU | GeForce RTX 2080 Ti | 11GB GDDR6 RAM |
| TPU | Cloud TPU v3 | 128GB |
タスク
自然言語処理タスクにおけるTPUとGPUの比較のために、以下の2タスクを行いました。
- Wikipediaの日本語データによるBERT (Bidirectional Encoder Representations from Transformers)の事前学習
- livedoor ニュースコーパスを用いた日本語テキスト分類問題に対する事前学習済みBERTのファインチューニング
TPUとGPUの比較
Task 1: BERTの事前学習
TPUとGPUの両方で、日本語のwikipediaデータを用いてBERTの事前学習を行いました。 今回選択したTPUとGPUでは搭載メモリが異なるため、ミニバッチサイズはTPUで256で、GPUで4としました。
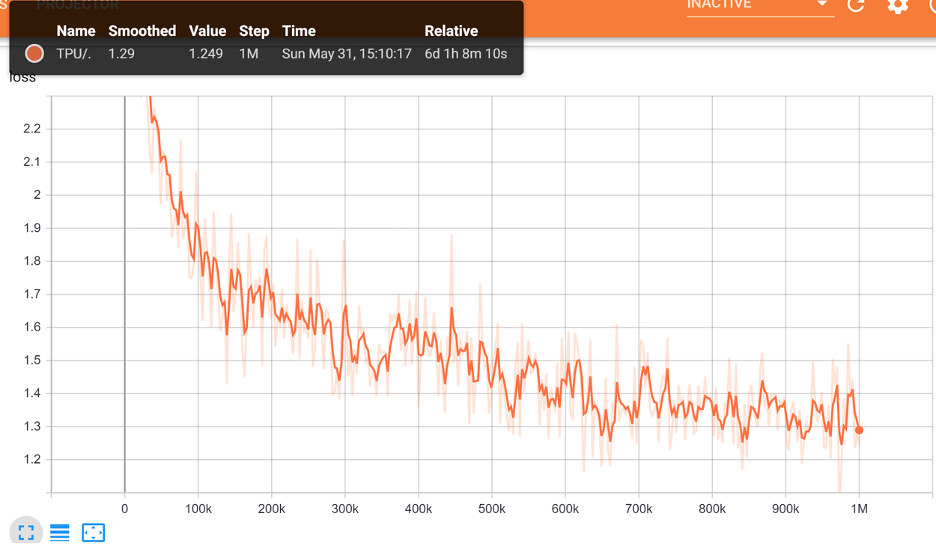
図2は、TPUによる100万ステップのBERTのlossを表示しています。
図3は、GPU上での事前学習中のBERTのlossを示しています。
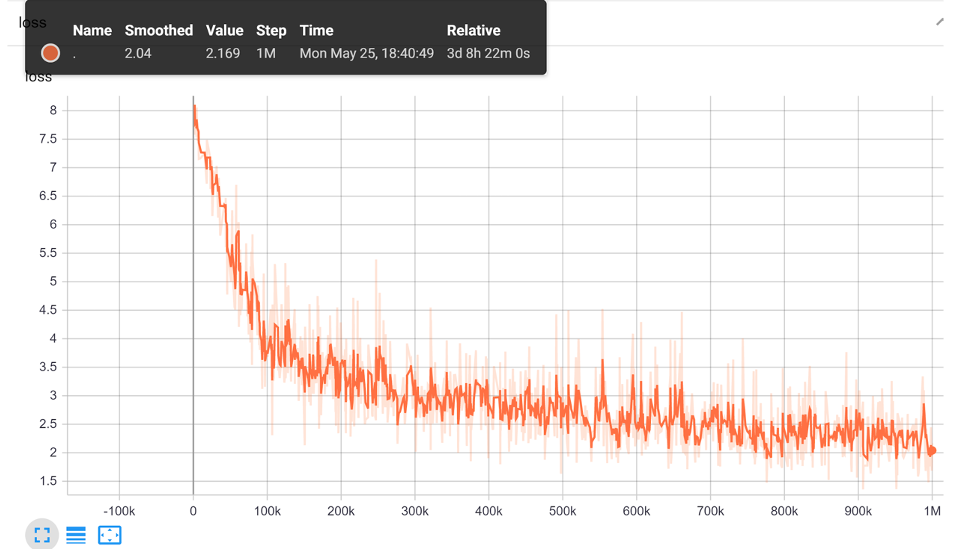
GPUの場合、1ステップにつき4つのデータが処理され、100万ステップで計80時間かかりました。つまり、GPUが1データを処理するのに、2E-5(80/4/1000000=0.00002)時間を必要とすることを意味します。TPUの場合は、1ステップにつき256つのデータが処理され、100万ステップで計145時間、つまり1データに5.67E-7(145/256/1000000=0.000000567)時間を要します。つまり、単純計算にはなりますが、BERTの事前学習においてTPUがGPUよりも 35 倍速く1バッチを処理しています。
Task 2: BERTのファインチューニング
ファインチューニングを行うタスクとして、livedoorニュースコーパスのテキスト分類を行いました(ミニバッチサイズはタスク1と同様にしました)。
GPUを使ったBERTのファインチューニングでは52分かかりましたが、TPUでのファインチューニングは5分でした。
終わりに
今回のタスクでは、TPUがGPUに比べはるかに高速という結果になりました。
また、leadergpu.comによると、GPUのレンタル料金は1時間あたり約0.7ドル、TPUは1時間あたり約8ドルです。 そのため、TPUの使用によるメリットは、高速化のみだけでなく、BERTのような大規模なモデルをトレーニングする際には安価であると考えられます。
謝辞
今回の比較では、Google社のTensorFlow Research Cloud(TFRC)のCloud TPUを利用させていただきました。
参考文献
- Jouppi, Norman P., et al. In-Datacenter Performance Analysis of a Tensor Processing Unit. 16 Apr. 2017, http://arxiv.org/abs/1704.04760.
