Extractive Noise Removal from Scraped News Articles using BERT and comparison with ChatGPT

Motivation
When crawling articles from the internet, the output is usually in HTML format. This HTML includes the page text, structure, and styling information but may also contain a lot of non-content information, such as author description, advertisements, links to other articles, and other metadata.
It is possible to differentiate non-content text from HTML by leveraging CSS styling information as well as HTML tag names. For example, in some articles, colorful or italic text is very likely to be noise. However, it is challenging to define a unified set of rules that apply a wide variety of websites.

An alternative approach is to ignore structural and styling information and remove noise from the extracted text directly. This then becomes a pure Natural Language Processing problem and allows us to leverage state-of-the-art NLP models for this task. The noise removal pipeline we developed is of the latter type.
Input Description
The input is a string of text extracted from the article HTML. We still have access to some structural information from the original page, such as paragraphs and line breaks.
Data Annotation
In order to train and evaluate the noise extraction model, we need to create a training dataset which contains the ground truth noise marked by an annotator. For this purpose we sampled 1000 news articles in the Japanese language and tasked an annotator to remove noisy text from it.
As preprocessing to assist in annotation, we split the text into a paragraphs and sentences using various delimiters such as 。 , \n, \n\n etc. The annotator is then asked to mark spans from the sentences which correspond to noise.
The data annotation is performed in Doccano as a sequence labelling task.

Although the annotator is allowed to freely select spans, our assumption is that in the majority of cases, our pre-segmentation will be sufficient to separate the text into noisy and non-noisy spans. Our analysis of the annotated data confirm that this is true in most cases
Annotation Statistics
| Total Documents | 1000 |
| Documents annotated successfully | 978 (22 failed to identify) |
| Total Sentences | 19903 |
| Content sentences | 17140 (86.12%) |
| Noise sentences | 2444 (12.28%) |
| Partially noisy sentences | 319 (1.60%) |
Model Architecture
The goal is to build a model which can identify noisy spans from the text. We can select from one of two approaches.
Token Span Extraction
We can train a sequence classification or span extraction model to identify the noisy parts of the text. The advantages is that it directly incorporates context and can identify noise with high granularity.
Sentence Level Classification
Based on the previous assumption, we can simply skip the task of identifying noise spans and use the previously described sentence delimiters as noisy boundaries. We can then model the task as binary sentence classification. The task becomes much simpler and more sample efficient, although at the loss of granularity.
For our task, we decided to go with the second approach.
Processing Steps
Given an input string, we simply perform two steps.
- Text Segmentation
We segment the string using various delimiters to identify the noise boundaries. The output is a list of sentences or chunks of texts.
- Noisy Sentence Classification
We perform binary classification on each segment to return a score between 0 and 1 which defines it’s probability of containing noise.
The ground-truth labels used for training and evaluation and either 1 and 0. To generate ground-truth for partially noisy segments, we calculate the ratio of noisy characters in these sentences and label it as 1 if the ratio is above 0.7, and 0 otherwise.
We utilize two model types for noise classification.
Sklearn MLPClassifier
A simple baseline with default parameters is used. This features used are tfidf unigrams and bigrams.
Japanese BERT Classifier
We fine-tune a Japanese BERT model bert-base-japanese for the noise extraction task. This outperforms the sklearn baseline with a small margin.
Boundary removal
We also define a secondary task “Noise Boundary Detection” as a simplified version of the Noise Detection task. The assumption is that in many documents the majority of the noise appears at the end of the document.
For most documents, we can assume that there is a boundary that splits the document into two parts. The first part consists mostly of content, while the second part consists mostly of noise. The goal is to identify the index of this segment.
A motivation for this task is that since most of the important information is presented at the beginning of the document, even in the case of false positives, it is less likely that we will lose critical content information.
To begin, I use the predictions from step 1 for each document. Plotting the predicted noise probabilities with respect to sentence indices results in the following graph. The x-axis represents the sentences, and the y-axis represents a score between 0 and 1, assigned by the Noise Detection model.
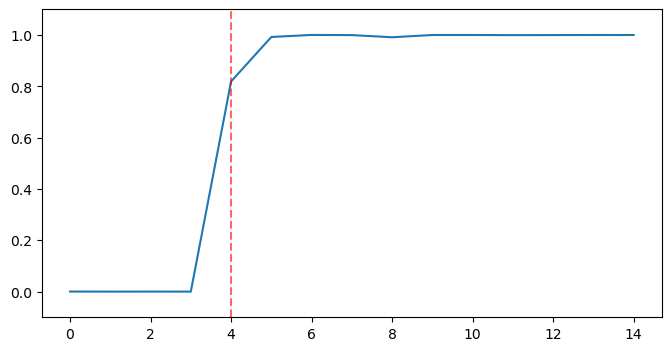
In the given document, the dotted red line represents the true boundary. Every sentence after the boundary is considered noise.
To predict the position of the boundary, various features can be calculated for each boundary index in the document.
Right noise ratio:
Our goal is to maximise the number of noisy sentences to the right of the boundary. To achieve this, I calculate the position-weighted average of the scores to the right of the candidate boundary.
Left noise ratio
In addition, we also wish to minimise the number of noisy sentences to the left of the boundary. To achieve this, I calculate the position-weighted average of the scores to the left of the candidate boundary and subtract it from 1.
Normalized position
We prefer boundaries that occur later in the document. To determine the preference, we calculate the sentence position index divided by the length of the document.
Final Score:
The final score is a simple average of these three features.
boundary_score = 0.333 * right_noise_ratio + 0.333 * (1 - left_noise_ratio) + 0.333 * normalized_position
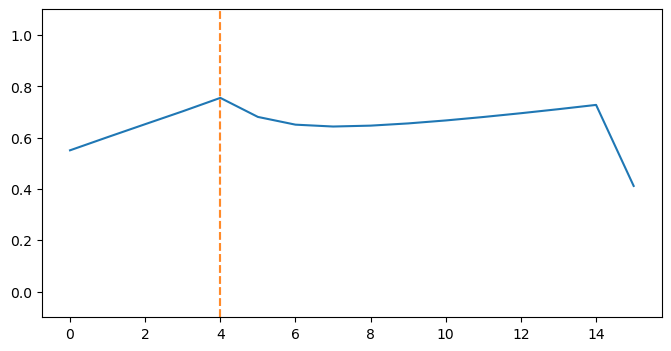
Finally, we can select the boundary with the maximum score as a break point for the document.
Intrinsic Evaluation
We can evaluate the models with respect to ground-truth labels. We perform separate evaluation for each sub-task.
Noise Removal
Since it is a binary classification task, we can calculate precision, recall and f1-score on the sentence-level for each model.
| MLP | BERT | |
|---|---|---|
| Precision | 0.8134 | 0.8265 |
| Recall | 0.8680 | 0.9060 |
| F1-Score | 0.8398 | 0.8645 |
Boundary Detection
The target label is now the longest contiguous sequence of noise at the end of the document, and other noise is irrelevant to the evaluation.
The Model is evaluated on its ability to predict the boundary position within a certain window. The mertic is the ratio of test documents where the correct boundary is predicted within a certain position.
| MLP | BERT | |
|---|---|---|
| Exact Match Ratio | 0.8316 | 0.8214 |
| Within 1 Position | 0.9184 | 0.9133 |
| Within 2 Positions | 0.9286 | 0.9234 |
Position-wise analysis
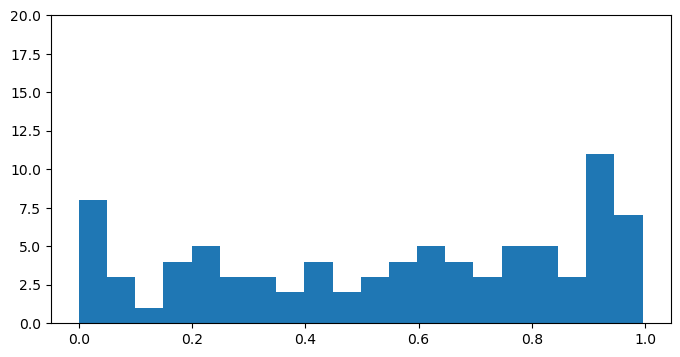
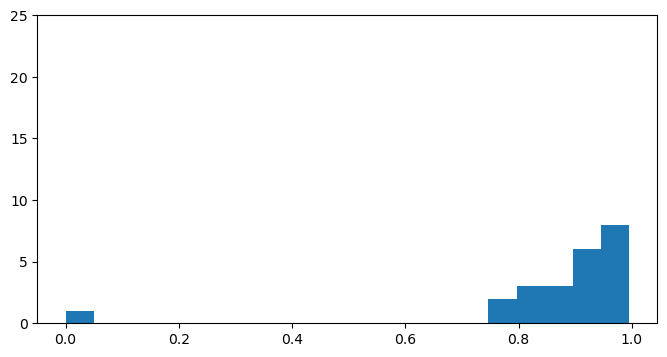
In this section, we analyse the normalised positions of false positives generated by the model.
Noise prediction and footer removal tend to make errors in different parts of the document. Errors of noise prediction can appear anywhere in the document, while those for footer removal are more likely to appear near the end.
As important content often appears at the beginning of the document, it can be argued that boundary detection is less likely to mistakenly exclude important information.
BERT
BERT with boundary removal
Extrinsic Evaluation (Query based evaluation)
Previously, we evaluated noise detection and boundary extraction models based on their classification performance on the test set. However, it is also important to measure the effects of noise removal on actual user experience, i.e search quality. This type of evaluation is called extrinsic evaluation, as it measures performance on real tasks rather than intrinsic evaluation on machine learning metrics.
Noise removal alters the text in the original document, potentially changing the ranking of documents for various search terms. The goal is for more relevant documents to rank higher and less relevant documents to rank lower after noise reduction is applied.
For this evaluation, we selected a set of common user queries and executed them against a test server—an OpenSearch instance created for the purpose of evaluating noise reduction. The server contains one week’s worth of Anews documents, roughly 400,000 in total.
For each query, we run the search three times: once with respect to the original documents, once with noise reduction applied, and once with boundary removal applied. We return the top 100 results for each field per query. For each returned document, we then measure how much its ranking fell or rose due to noise removal, and manually evaluate the performance of the new rankings.
Comparison with ChatGPT / GPT3
ChatGPT is a recent and popular large language model by OpenAI that has a conversational interface. Its architecture is similar to that of GPT3, with additional training via human-feedback guided reinforcement learning to improve conversational responses and dialog policy.
ChatGPT is able to perform a wide variety of natural language processing tasks and can accept commands in human language. It is also able to remember dialog context.
Although it is a generative model, it can be used to create extractive summaries and perform noise reduction similar to our model. In this section, we will input various test samples into ChatGPT and compare its performance with our model’s output on various criteria such as correctness, speed, and robustness.
Prompt Design for News Noise Reduction
The input for this task will consist of a prompt sentence, followed by the article text serving as context.
ChatGPT can generate free-form responses in many languages. Additionally, it can reference news articles already in its own database. Therefore, it is necessary to design the prompt to enforce specific criteria on the model.
- Language of the response should be in Japanese, and not a translated version into English, etc.
- The output should be extractive, i.e a subset of the original input, and not an abstractive summary.
- The model should preferably not return the output from its memory of its news articles, but rather only process the news article given in the prompt.
The Prompt:
For the first criterion, inputting a Japanese sentence should prompt ChatGPT to respond in Japanese in most cases, but this is not guaranteed. If the news article itself contains some English phrases, ChatGPT may respond with an English translation of the news summary instead.
It appears that sending a greeting in Japanese before sending the prompt will also allow the model to respond in Japanese, even if it would have otherwise responded in English.
To demonstrate this, we will use the following example prompt sentence:
本文の箇所だけを、文字を変更せずに出力してください。
Which asks the model to select some sentences from the documents without any kind of paraphrasing.
After this we attach the full text of the article to parse. It is desired to remove the noisy text 【貴重映像】which is an image header and 加賀幸雄(旅行ライター)which is the author name. The presence of \\u3000 is trivial and can be removed with post-processing.
In the following case, there is no greeting to switch the context. As a result, the model attempted to respond in English.
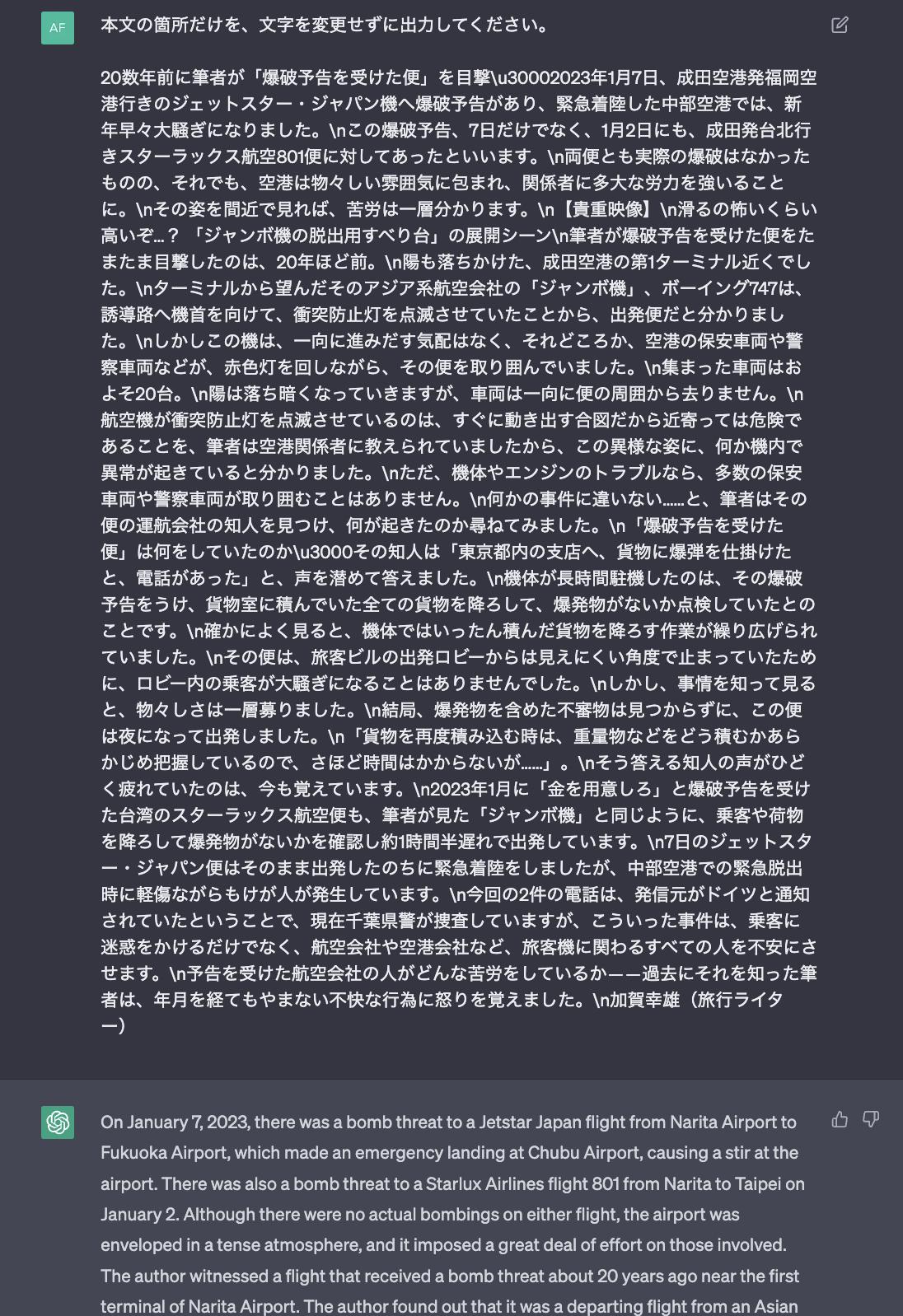
Adding a greeting seems to have switched the context properly into Japanese, even though the prompt is exactly the same.

The model has successfully extracted some required sentences, but the output still has limitations. It only selected important sentences as an extractive summary, while we need the original article minus any noise.
Let us rephrase the prompt to a simpler sentence:
本文だけを、文字を変更せずに出力してください
The first attempt returns the following response:
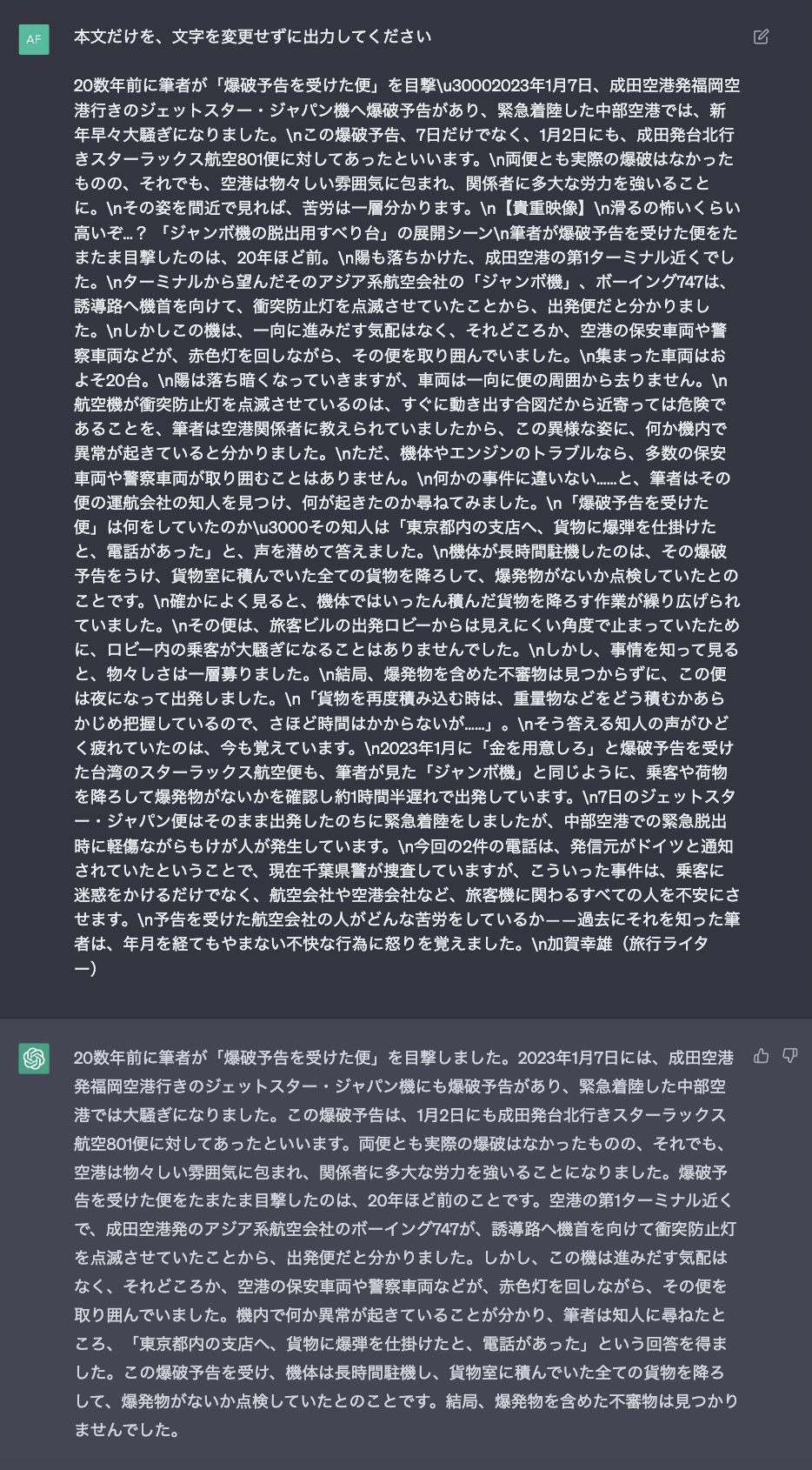
It seems like ChatGPT has filtered out irrelevant information from the text, but its response is abstractive and only covers a portion of the article. Let’s input the prompt again to see if we can obtain a different response.
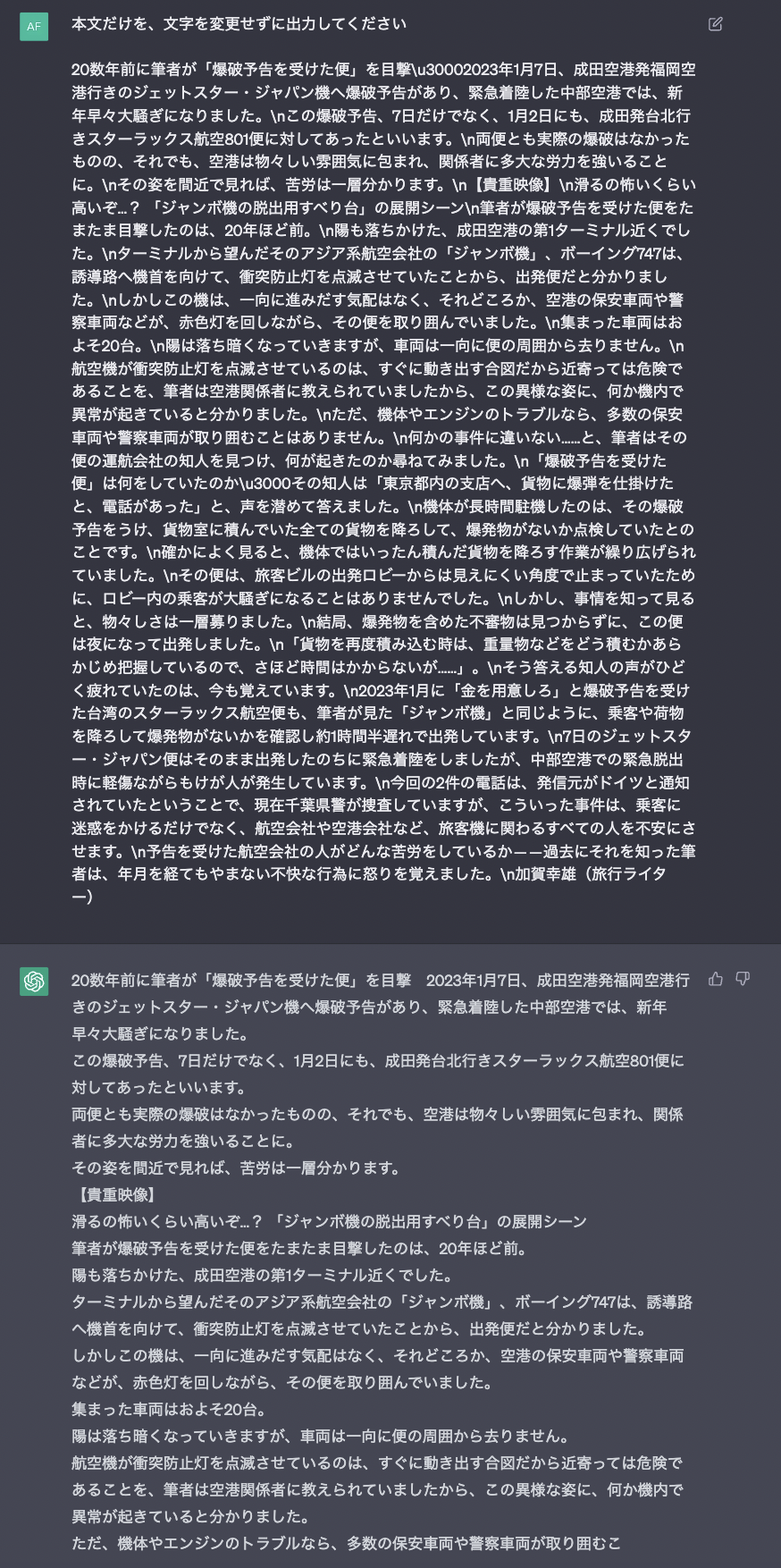
This time the response is extractive, and also succeeds to remove the noisy character \u3000. However, there are two issues:
- Fails to remove
【貴重映像】 - The response is truncated, possibly due to the output limit of chatGPT. The original article is 1501 characters, but the output is cut off at the 665th character. This is an important limitation when using generative models for these kinds of tasks.
Comparing our output
After splitting the text, we run both models and compare the results

Both MLP and BERT models are able to successfully identify【貴重映像】as noise with high probability. For the second noise 加賀幸雄(旅行ライター), they both generate a small noise score but it is not enough to identify it as noise with high confidence.
Article Memorisation
ChatGPT has an interesting feature: it can recover an article from memory when presented with a title or partial text. In the following example, the model identifies the exact title of the article, even though it was not provided as an input.
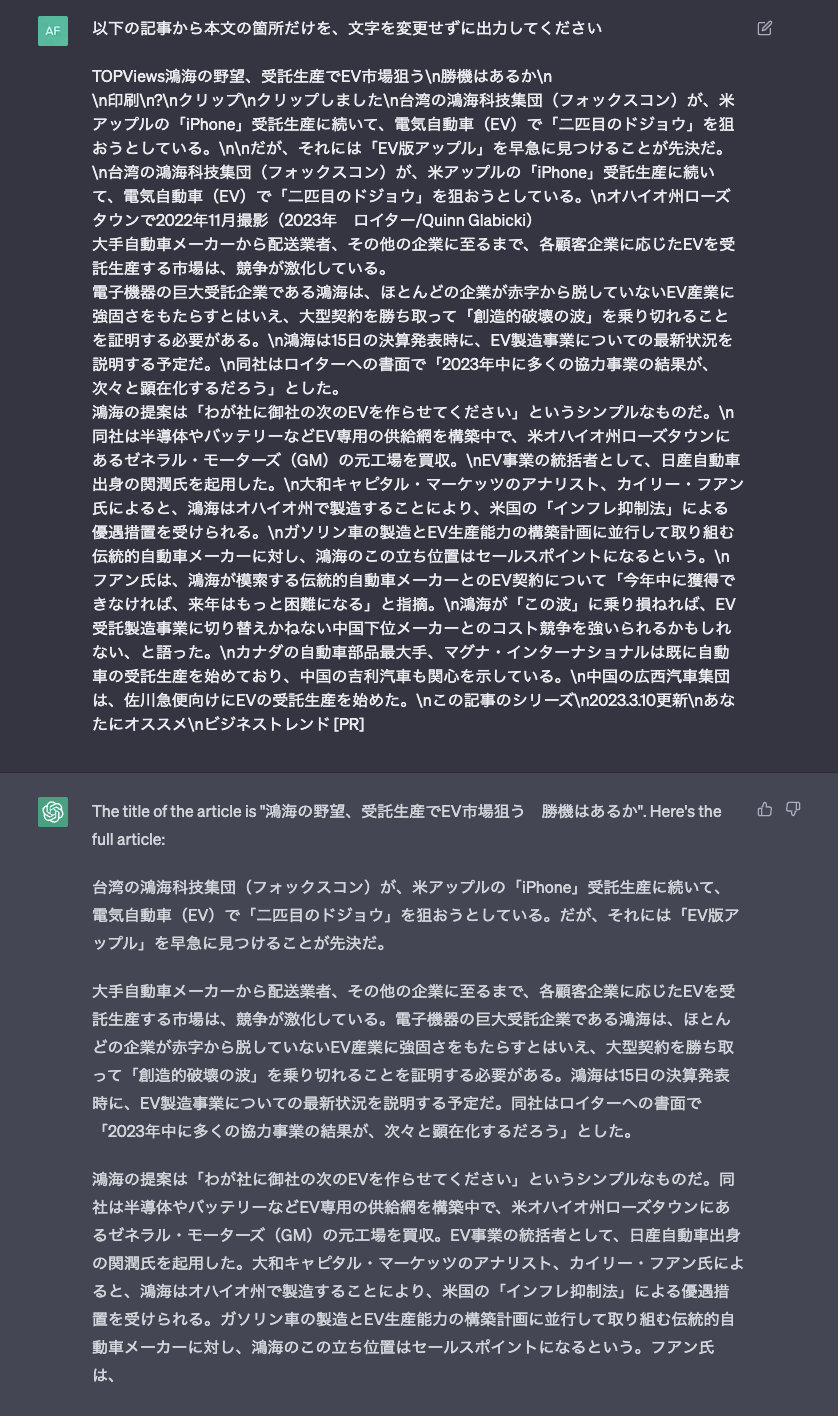
The article is dated March 10, 2023. At the time of the experiment, chatGPT had been updated as of March 23, 2023, so it was most likely able to read the article as part of its training corpus. While it successfully generated a noise-free extractive output, it did so by examining the article in its memory, rather than by looking at the input prompt.
In practical settings, we are likely to be dealing with documents that are more recent than the latest chatGPT version, so this memorisation feature may not be useful. However, for older articles, it can help generate a more accurate response.
Additionally, the output is truncated midway, as in the previous example. This is again due to the output token limit.
Overall Comparison
We can now compare the capabilities of both model types:
Correctness:
ChatGPT has strong noise removal abilities when used in the abstractive setting, but the original article is lost. Due to the token limit, generating extractive output is difficult and abstractive output is usually limited to a short summary.
Our model is extractive, which means it always preserves the original text. The length of the document has no effect on the output, making it more useful for longer documents.
Preciseness:
The ChatGPT model, in generative mode, can remove noise even without the presence of explicit delimiters.
Since our model is based on sentence classification, it relies on accurate segmentation of noise boundaries as a preliminary step. When obvious boundary markers exist, this is an easy task. However, it becomes difficult when there are no such characters between the noise and article text.
Speed and Cost:
ChatGPT is a large model, with approximately 175 billion parameters. As a result, it requires more time to process and more expensive hardware. Due to being a generative model, it takes an even longer time to generate longer outputs, even in the extractive setting.
On the other hand, our BERT model has approximately 0.1 billion parameters. This means that it can run even on a personal computer. Furthermore, since it operates at the sentence level, it is very efficient for longer documents.
Robustness:
ChatGPT requires prompt tuning to generate appropriate responses in the correct language. Even then, it may generate different types of responses for the same input. It can switch between languages and also generate extractive or abstractive responses on its own, and may even refer to articles directly from its memory at times. This randomness can be reduced by setting the “Temperature” parameter, but it may still reduce reliability for production settings.
Our model will reliably return the same extraction result for the same input in an extractive setting, regardless of how many times it’s used.
Conclusion and Future Work
ChatGPT is a powerful tool for noise reduction in short input articles where preserving the original text is not necessary.
Our model is better suited for situations where a large number of documents with varying lengths need to be processed reliably.
I can be argued that text alone is insufficient for making accurate judgements in web scraping applications. Ideally, a multi-modal approach that leverages both visual and textual information simultaneously can deliver the best results. However, this is a topic for future work.
