Anewsの裏側で動く、自然言語処理を活用したビジネスニュースの推薦システム
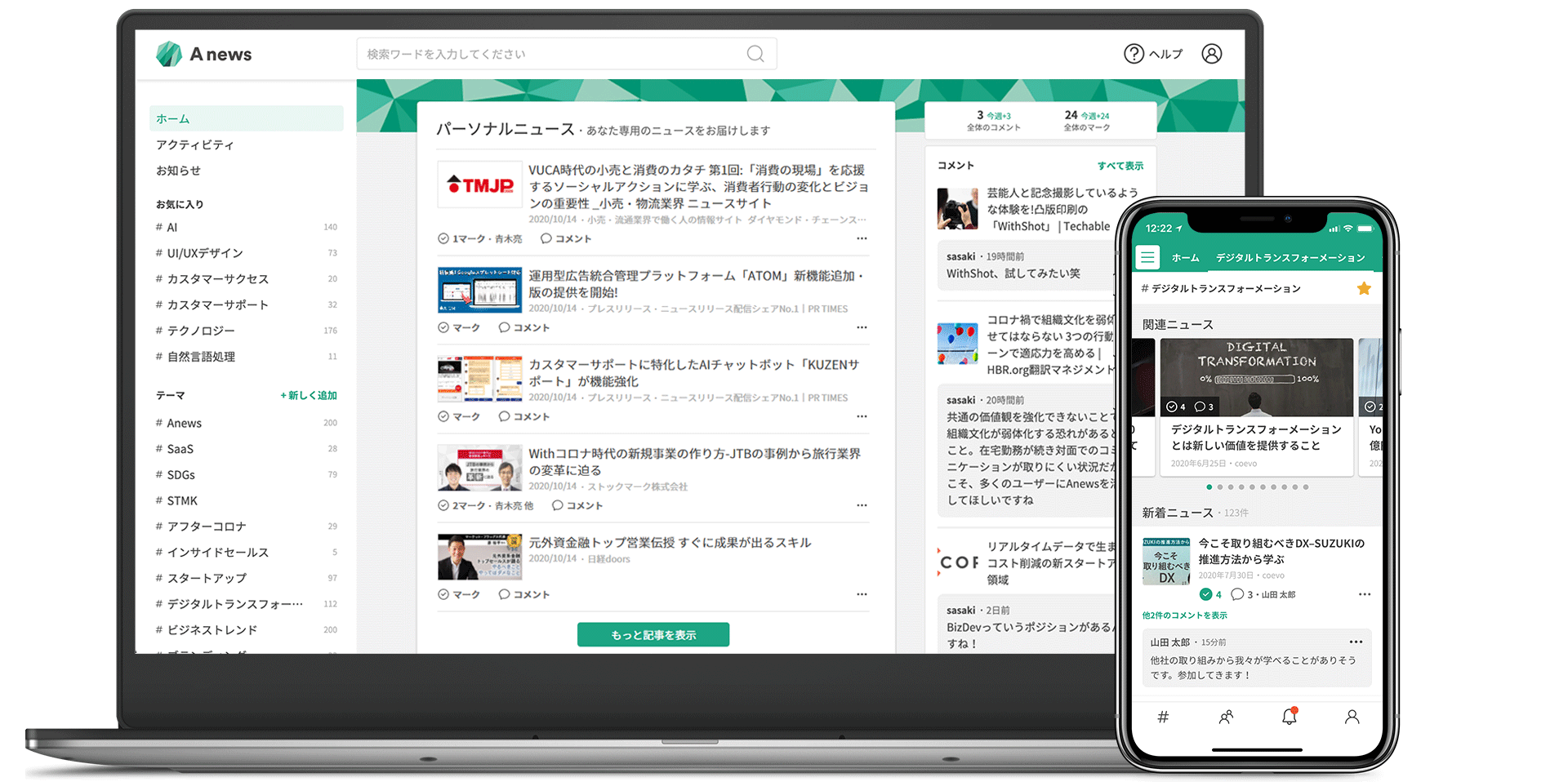
ML事業部の金田です。今回は、ストックマークの提供する法人向けサービス「Anews」の裏側で動くビジネスニュース推薦システムについて、簡単に紹介いたします。
Anewsとは
Anewsは組織変革のための情報収集+コミュニケーションプラットフォームです。
情報収集のためのコア機能としては、国内外3万メディアから収集したビジネスニュースから、利用者の興味・関心に合わせて記事を配信するサービスを提供しています。日々配信されるニュースから業務ニーズに直結するインサイトを獲得し、これを話題にユーザ同士が交流することで、組織全体の情報感度やコミュニケーションを促進させるのが、サービスの狙いです。
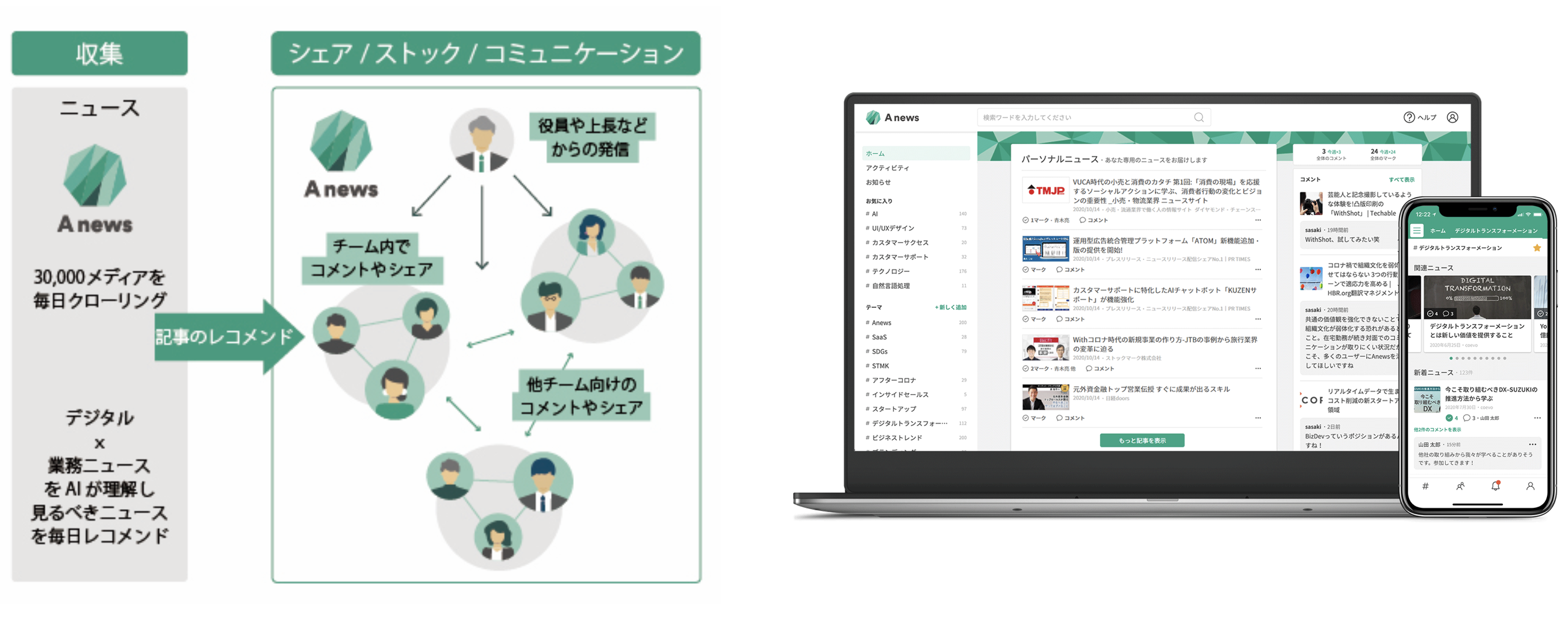
事前準備:ことばの定義
具体的な機能説明の前に、Anewsにおける基本的な概念について軽く整理します。
Anewsは1企業=1集団としての利用を想定しています。以降ではこの集団をチーム、チームに所属する各利用者をメンバーと呼ぶことにします。ニュース配信の際に利用する情報は、基本的にチーム毎に独立しています。
各チームでは、特定の話題を追うためのチャンネルであるテーマを作成することができます。テーマに存在するテーマフィードには、設定されたキーワードにマッチするようなニュースリストが一日一回配信されます。
一般に、レコメンデーションシステムではコールドスタート問題の解消が課題とされます。これは、サービスを初めて利用するユーザに発生してしまう、次のような問題です。
- 初利用するユーザからは興味・関心を表す手がかりが得られないため、よいレコメンドが行えない
- よいレコメンドが行われないため、ユーザが自身の興味・関心を提示する前に離脱してしまう
テーマフィードでは初期設定時のキーワードを手がかりとすることで、この問題に対処しています。
メンバーはフィード上のニュースに対し、自由に閲覧、マーク、コメントといった行動をとることができます。これらの行動は、より良いニュースを配信するための手がかりとして利用されます。テーマフィードに配信されるニュースリストはメンバーに依らず同一であるため、これを共通の話題として扱うことができます。
行動履歴が一定以上蓄積したメンバーに対しては、一人ひとりの嗜好に合わせたニュースリストを、個人フィード上に一日一回配信しています。こちらは各メンバーの持つ興味/知識の更なる深堀りを意図した機能です。
このように、メンバーの興味・関心に合わせてコンテンツ配信を実現する推薦システムがAnews内部には組み込まれています。
Anewsのニュース推薦システム
基本コンセプト
Anewsのニュース推薦システムでフィードに配信する記事を決定する際には、「行動がなされた記事の集合」を手がかりとして利用します。
個人フィードでは、「任意の場所で、該当メンバーによって行動がなされた記事」を手がかりとします。「メンバーは、自身の嗜好(=興味・関心)にマッチした記事に対して行動する」と仮定すると、この記事集合は、「メンバーの嗜好を表す記事の集合」として捉えることができます。よって以降では、これを「メンバーの嗜好記事群」と呼ぶことにします。
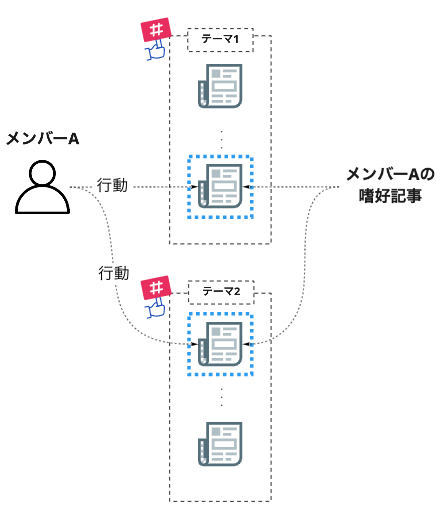
一方テーマフィードでは、「該当フィード上で、任意のメンバーにより行動がなされた記事の集合」を手がかりとします。こちらは「テーマの嗜好記事群」と呼ぶことにします。
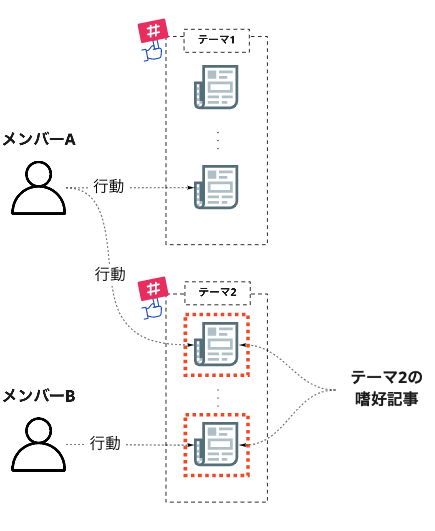
記事をフィードに配信する際は、それぞれの嗜好記事群と意味的に近い記事を候補の中から選びます。これは、「過去に反応を示した記事と似ている記事に対しても、ユーザは同様の反応を示す」という仮定に基づいています。
このようにコンテンツ(記事)の内容比較による推薦は内容ベース推薦と呼ばれます。一方で、「この商品を買ったユーザはこのような商品も買っています」と言った文言に代表されるように、別のユーザの行動を参照して推薦を行う手法は協調型推薦と呼ばれます。toBサービスであるAnewsは、toCサービスに比してユーザ数が少なく、ユーザ毎の利用動機のばらつきも大きいため、協調型のアルゴリズムを利用する領域は一部に限られています(今回の紹介範囲には含まれていません)。
ただし、意味的な近さを考慮する際には注意点があります。嗜好記事群には、複数の話題が混在する場合があります。配信候補記事と嗜好記事群を比較する際には、嗜好記事群に暗黙的に含まれうる様々な話題を考慮した上で、意味的な近さを計算する必要があります(例えば、話題AとBの二つに興味のあるメンバーには話題AまたはBに関連する記事を配信したい)。
要素技術: 概要
上記コンセプトを実現する要素技術としては、次の3つが挙げられます。
- 記事の意味的な近さを定量的に計算するため、記事の意味をベクトルで表現する
- 嗜好記事群に混在しうる複数の話題を適切に分離するため、嗜好記事群をクラスタリングする
- クラスタリングされた嗜好記事群と配信候補記事の類似性を、いくつかの指標でスコアリングした上で各スコアを統合し、最終的なスコアの高い記事を推薦する
技術3. についてはやや職人芸的要素が強く話が複雑になってしまうため、以降では主に1.と2.について紹介します。
要素技術1. ニュース記事の意味をベクトルによって表現する
当社では、国内・国外合わせて約3万メディアから、日々数万〜十数万件のニュースを収集しています。収集された記事は解析、構造化の後データベースへ格納されます。アプリケーションで利用可能な記事の情報としては、次のようなものが挙げられます。
- タイトル
- 本文
- 記事の公開日
- サムネイル画像
- etc
記事のベクトル化(記事ベクトル作成)に際しては、これら情報のうちタイトル及び本文、すなわちテキストデータのみを利用しています。テキスト(文章)の表す意味をベクトル化する手法は数多く提案されていますが、Anewsにおいては以下を採用しています。
- テキストに含まれる単語にベクトルを割り当てる
- 割り当てられたベクトルを単語の重要度に準じて重み付けし、足し合わせる
具体的には、1.においてはWord Embeddingと呼ばれるモデルの一種であるfastTextを、2.の重みについてはSIFを利用しています。両者は近年隆盛を誇っているTransformerモデル以前の技術ですが、Anewsでは以下のような背景から、実装/運用コスト等を含め総合的に判断した上で採用しています。
- Anewsは一度プロダクトの刷新を行っている。この際には推薦アルゴリズムも一から書き直すことになったが、検証〜実装に使える時間は限られていた。
- word embeddingベースの手法はCPUで学習・推論が可能であり、アプリケーション応用のハードルが低い。また刷新前のAnewsでも利用実績があり、一定の知見・成果を得ていた。
- 社内データを利用してm~USE, LaBSE等の最新モデルとの性能比較を行ったところ、目立ったパフォーマンスの劣後は見られなかった。
以降では、軽くWord EmbeddingとSIFの性質についても触れてみます。
Word Embeddingは単語に対し、その出現文脈に依存せず一意のベクトルを割り当てます。つまり、これだけでは動物を指す「ライオン」と、企業を指す「ライオン」を区別することはできません。
しかし、語義が異なれば、文中に現れる単語も異なることが想定されます。企業の「ライオン」に言及した記事であれば、「歯ブラシ」、「新製品」といった単語が文中に現れるでしょう。一方、動物の「ライオン」に言及した記事であれば、「動物園」「サバンナ」といったような単語が文中に現れるでしょう。
これら文中に現れる単語のベクトルを適切に重み付けして足し合わせることで、「企業のライオンについて言及している記事」と「動物のライオンについて言及している記事」の区別が可能になります。
SIFはWord Embedding同様、単語に対し、出現文脈に依存せず、一意の重みを割り当てます。この重みは、高頻度で出現する単語ほど小さくなります。例えば助詞の「を」や「が」は、多くのニュースにおいて高頻度で出現する単語です。これらの単語に対する重みを小さくすることで、SIFは「不要な単語を無視する」ような働きをします。
ちなみに、これらの具体的な意味を持たない頻出単語は、自然言語処理において「ストップワード」と呼ばれます。古典的な自然言語処理において、ストップワードは前処理段階で除外されるのが理想とされます。しかし、SIFを利用する場合、この処理を挟まずとも高品質な記事ベクトルを作成することができるため、実装がシンプルになるというメリットがあります。
要素技術2. 嗜好記事群をクラスタリングする
記事をベクトルによって表現することで、一般的なクラスタリング手法をそのまま適用することが可能になります。ここでは、コサイン距離(=1-コサイン類似度)を用いたウォード法を採用しています。
ウォード法は次のような性質を持つクラスタリングアルゴリズムです。
- 各要素を、必ず特定のクラスタに結びつける(ハードクラスタリング)
- 各要素を独立したクラスタに入れ(N要素の場合はNクラスタができる)、終了条件を満たすまで近接クラスタ同士を結合していく(凝集型クラスタリング)
終了条件にはいくつか設定の余地があるのですが、嗜好記事群のクラスタリングにおいては「結合を許すクラスタ間距離にしきい値を設ける」方法を採っています。このしきい値を入力された記事群に応じて動的に調整することで、次のような要求に対応できるようにしています。
- ユーザが追いたい話題の数にはばらつきがあるため、話題数に応じてクラスタ数を調整したい。
- ユーザが追いたい話題の分散にはばらつきがある。狭い領域の中で微妙に異なるトピックを追いたい場合(例:「他社における自然言語処理技術の応用事例」と、「自然言語処理の最新技術動向」)もあれば、広い領域の中で全く異なるトピックを追いたい場合(例:「自然言語処理」と「プロダクトマネジメント」)もある。クラスタ数を決める際には、このブレを吸収できるようにしたい。
要素技術3. 配信候補記事をスコアリングする
配信候補記事をスコアリングする際には、複数の観点から評価を行います。
一例として、「メンバーの嗜好との意味的な近さ」を表す指標としては、「各嗜好記事クラスタの重心(セントロイド)とのコサイン類似度」を利用しています。また、テーマにおいては「設定されたキーワードから作成したベクトルとのコサイン類似度」等も利用しています。
これらの指標を重み付けして足し合わせることで、最終的な推薦スコアを算出します。このスコアに応じて記事を並び替えたときの上位n記事が、それぞれのフィードに対して配信されます。
補足:その他の工夫
ニュースの推薦を行う際には、ここで紹介した以上に様々な工夫がなされています。
例えばニュース記事のベクトルを作成する際には、テキストの品質が非常に重要となります。ニュース記事の本文には意味をなさないテンプレート文が付属していることがあり、この存在は作成されるベクトルに悪影響を及ぼします。そのため、テンプレート文を除外する仕組み( Boilarplate Removalと呼ばれる技術)が入っています。
また、複数のメディアからニュース記事を収集する以上、配信候補には同一の事柄に言及したニュースが複数含まれます。内容の重複する記事が同一フィードに複数配信されてしまうと、ユーザの体験を損ねることになってしまうため、この重複を除去する技術(社内では転載記事集約と呼称)も実装されています。
Anewsは国内メディアだけでなく、海外メディアのニュースも配信しています。国内メディアの記事を読むだけで、海外メディアの記事も適切に推薦されるよう、嗜好を多言語間で共有する仕組みも実現しています。
結び
以上、簡単ではありますが、Anewsの裏側で動くニュース推薦システムの裏側について紹介いたしました。Anewsは累計1,500社を超えるお客様から利用されていますが、システムとしてはまだまだ発展の余地を残しています。興味を持っていただけたた方はぜひWantedlyの方もご覧いただければと思います!
