Cloud TPUを用いたBERT推論処理基盤の開発
ML事業部の近江崇宏です。
Stockmarkでは日々、膨大な数のニュース記事に対してBERTの推論処理を行なっています。このような重いタスクを効率的に処理するために、最近、TPUを用いたBERTの推論処理基盤をGoogle Cloud Platform上に構築し、運用を開始しました。その結果として、これまで1週間程度かかっていた、数千万件のデータの処理を1日以内で完了できるようになるなどの大きな効果を得られました。今回はこの取り組みについて紹介します。
はじめに
近年のニューラルネットワークの研究の発展により、画像認識や自然言語処理の様々なタスクを人間と同等もしくはそれ以上のレベルで処理できるようになりました。その結果として、ビジネスでのニューラルネットワークの利用が進んでいます。その一方で、ニューラルネットワークには、モデルの巨大さに起因して処理時間が長いという大きな問題があります。そのため、それらを適切にコントロールすることが、プロダクトでのニューラルネットワークの活用が成功するかどうかの重要な鍵になっています。
一般的には、モデルを学習するときの処理時間の長さが問題とされることが多いですが、これは推論でも大きな問題となり得ます。特にStockmarkでは、BERTと呼ばれる自然言語処理のためのニューラルネットワークを用いて、膨大な数のニュース記事に対して分類や抽出などの推論処理をしており、これにかかる時間の削減がプロダクトでの大きな課題になっています。具体的には、
- 新規のニュース記事(数万件)に対する日次のバッチ処理
- 新たなモデルがプロダクトに追加された場合や、アルゴリズムの変更や学習データの追加により既存のモデルが更新された場合に行われる、データベースに保存されている過去のニュース記事(数千万件)に対する全件処理
などの日々のオペレーションでBERTの推論処理を行なっています。そのため、このような大規模なデータに対して効率的に推論処理をするための強力な処理基盤が必要になりました。
StockmarkではこれまでBERTの推論を主にGPUを用いて行なってきましたが、Googleが開発した行列演算などの機械学習の処理に特化したチップであるTPUを用いて、データ処理を効率化する取り組みを最近始めました。そして、新たな処理システムをGoogle Cloud Platform(GCP)上に構築し、日々のオペレーションで運用しています。今回のブログでは、これについてのStockmarkの取り組みについてご紹介します。
Cloud TPUを用いた推論処理基盤
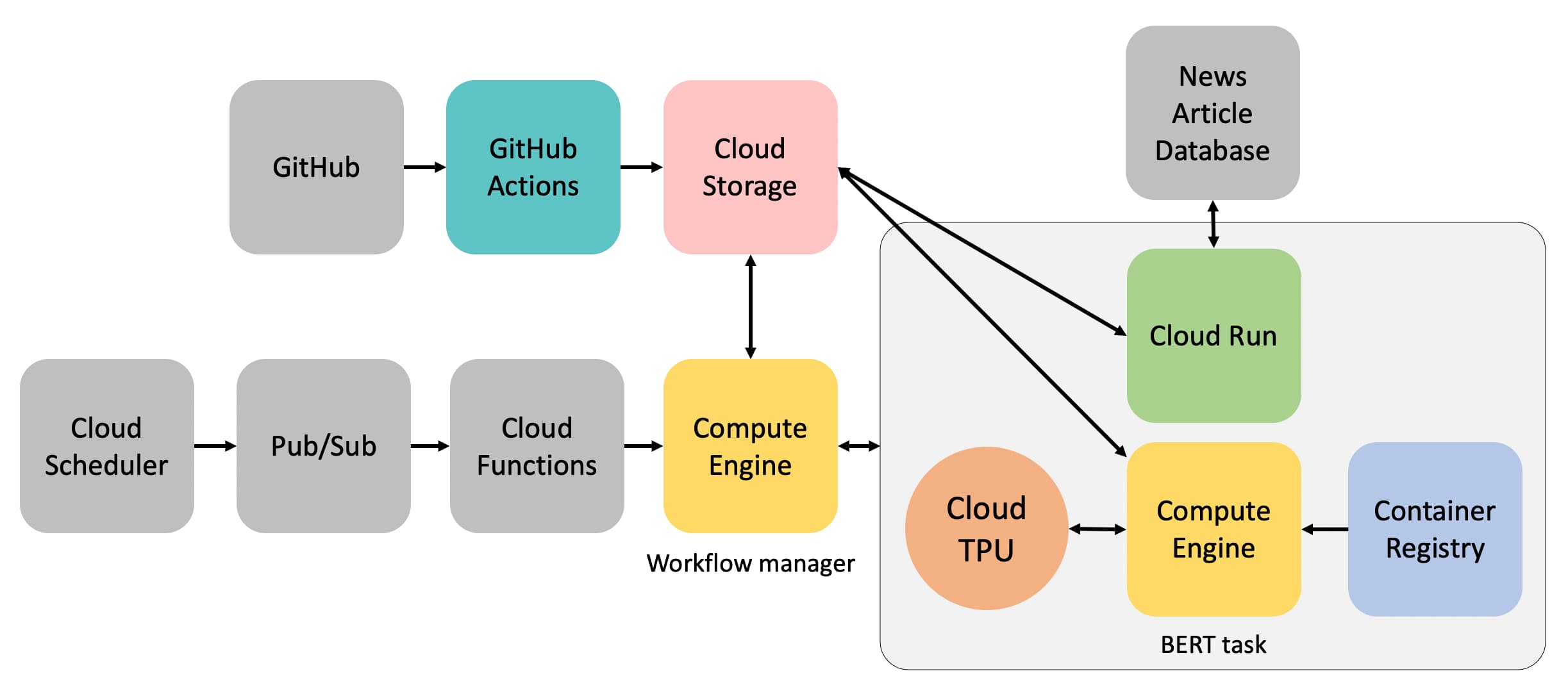
システム概要
ここでは、GCPに構築したBERTの推論処理のためのシステムの概要について紹介します。
GCP上でCloud TPUを用いるためには、まずTPUのノードを別途起動させる必要があります。その後にCompute EngineのインスタンスからTPUにアクセスするような形で、TPU上で計算ができます。
日次のバッチ処理では、ニュース記事をデータベースから取得し、BERTによる推論処理をし、その結果をデータベースに返すという一連の流れが実行されます。このために、以下のようなアーキテクチャーを用いました。
- 毎日指定された時間になると、Cloud Schedulerが起動し、Pub/Subを通して、Cloud Functionsをトリガーする。
- Cloud Functionsはワークフローを管理するためのインスタンスを作成する。
- このワークフローを管理するインスタンスが以下のタスクを順次実行する。
- Cloud Runを用いてデータベースから処理するニュース記事のデータを取得し、Cloud Storageに保存。
- 推論処理のためのインスタンスとTPUのノードを作成する。このインスタンスはContainer Registryから取得したコンテナ上でBERTの推論処理をTPUで行い、処理結果をCloud Storageに保存。タスク完了後にインスタンスを削除。
- Cloud Runを用いて処理結果をデータベースに返す。
- 全ての処理が完了後、処理結果をSlackに通知し、自身のインスタンスを削除。
** 参考までにCloud Runはサーバレスの計算環境でコンテナ上のアプリケーションを実行することができ、自動スケーリングなどにも対応しています。
MLOps
以前、ブログで紹介したようにStockmarkではMLOpsの考えを取り入れたシステム開発を行なっており、今回の開発でもMLOpsの概念に基づき、以下のようにCI/CDをできる限り自動化しました。
- GitHubの特定のレポジトリにコードがpushされると、GitHub Actionsを通じて自動的にCloud Storageの特定のバケットにコードがアップロードされる。各インスタンスは起動時に、そこからコードを取得し、タスクを実行する。
- Cloud buildを用いたCloud Functions、Cloud Run, Container Registryへのデプロイ。
Cloud Runを用いた全件処理時の工夫
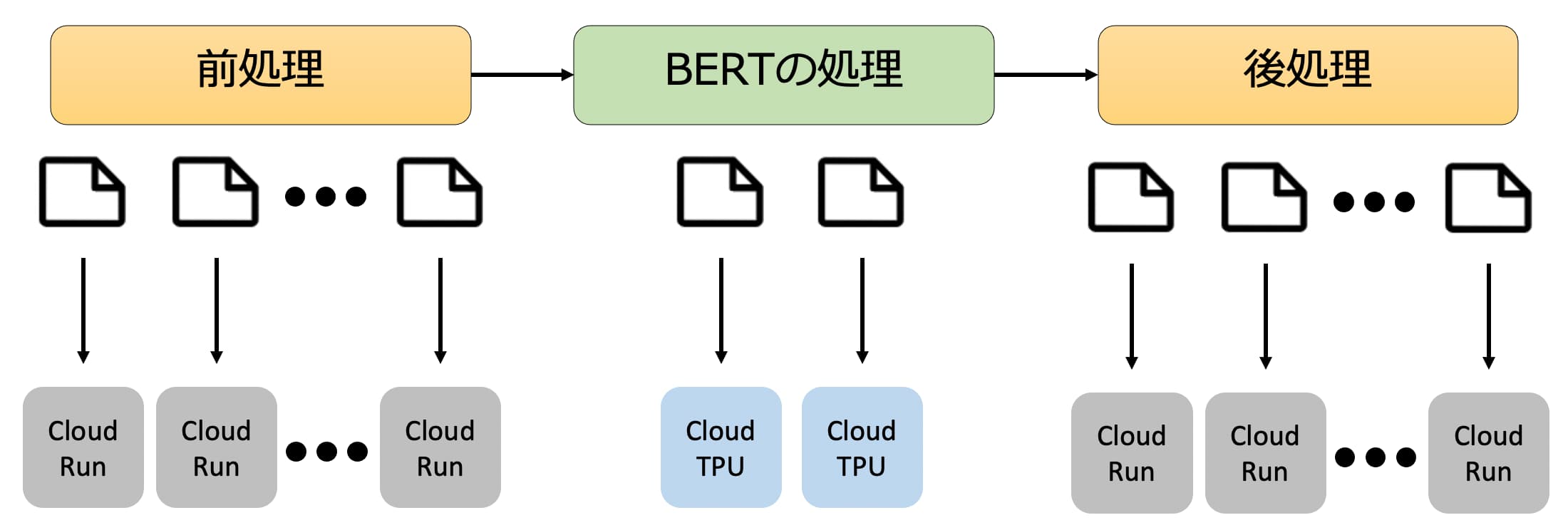
全件処理の際にも、上をベースとしたシステムを用いますが、さらなる処理の高速化を図りました。
数千万件のニュース記事の処理する際には、データの前処理や後処理にも、かなりの時間がかかります。そこでデータ処理のワークフローを(i)形態素解析などのデータの前処理、(ii)BERTによる処理、(iii)後処理の3段階に明確に分離しました。そして、CPUで計算を行うデータの前処理と後処理はCloud Runを用いて最大で100程度のインスタンスを用いて並列しました。Cloud Runはリクエストに応じて自動的にインスタンスが増えるので(自動スケーリング)、多数のインスタンスでの効率的な並列処理が可能になりました。さらにBERTの処理では2つのTPUのノードを用いました。このようにして、処理全体を高速化しました。
Cloud TPU導入の効果
Cloud TPUを導入することで、特に全件処理時のパフォーマンスが著しく向上しました。GPUサーバを用いて処理を行なっていた時には、1週間程度の時間がかかっていましたが、Cloud TPUを用いることにより1日以内に処理を終えることができるようになりました。
以前は、日々のオペレーションの課題は、新規のニュース記事に対する日次のバッチ処理をいかに安定的に行うかということにありました。しかし、最近ではチームの人数の増加やプロダクトの成長により、新しいモデルを開発したり、既存のモデルを改善をする頻度が増えており、この際に発生するデータの全件処理をいかに早く行い、開発サイクルを早く回すかが重要な課題になっています。処理時間が大幅に短縮されたことで、お客様に新しい機能をより迅速に提供できるようになるといった効果が期待されます。
TPUとGPUのパフォーマンス比較
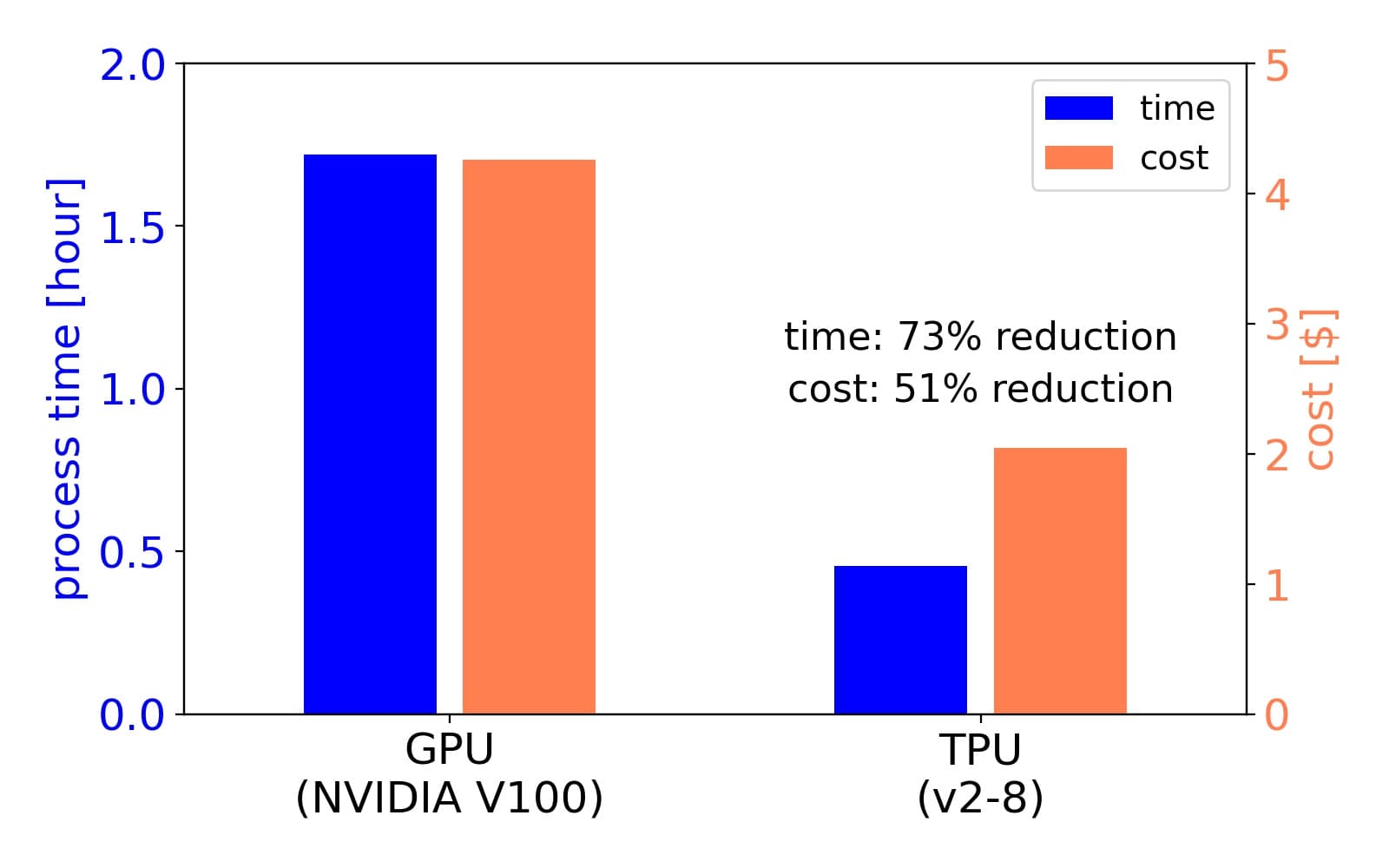
BERTの推論処理を行う上で、TPUがGPUに比べるとどの程度、処理時間やコストを削減できるかについても検証しました。ここでは、ベンチマークとして約50万のニュース記事を用いて、BERTの推論処理にかかる時間とコストをTPUとGPUで比較しました。タスクとしては、文章中から企業名を抽出するタスク(詳しくは過去の記事をご覧ください)を用いました。結果は下のようにまとめられ、TPUを用いるとGPUと比較して処理時間が73%、コストが51%削減することができることがわかり、大規模なデータの処理でのTPUの優位性がわかりました。
** 学習時のTPUとGPUの性能比較については過去のブログをご覧ください。
TransformersのBERTをTPUで動かす。
今回はTransformersのTensorFlowのBERTを用いました。まず、GPUを用いる場合には、モデルのロードは例えば以下のような感じです。
from transformers import TFBertForTokenClassification
model = TFBertForTokenClassification.from_pretrained(MODEL_PATH)
TPUを用いる場合には、上のコードを以下のように変えるだけです。(参考:https://www.tensorflow.org/guide/tpu)
import tensorflow as tf
from transformers import TFBertForTokenClassification
resolver = tf.distribute.cluster_resolver.TPUClusterResolver(tpu=NODE_NAME)
tf.config.experimental_connect_to_cluster(resolver)
tf.tpu.experimental.initialize_tpu_system(resolver)
strategy = tf.distribute.TPUStrategy(resolver)
with strategy.scope():
model = TFBertForTokenClassification.from_pretrained(MODEL_PATH)
NODE_NAMEはGCP上で作成したTPUノードの名前です。
TPUを用いる上での工夫
TPUで最適なパフォーマンスを得るために下のような点に気をつけました。
TPUは8個のコア、64GBのメモリを持っており、GPUに比べると多くのデータを一度に処理できます。そのため、バッチサイズをできるだけ大きくすることで、処理が効率的になります。
GPUと比べてTPUは初期化やモデルのロードに時間がかかることにも注意が必要です。以前に、GPUで処理をしていた時は、その時に処理するデータをいくつかのファイル(例えば1万記事ごと)に分割して、それぞれのファイルにスクリプトを実行していました。しかし、TPUの場合には、データを分割して処理すると、それぞれのファイルを処理するたびに、上記のオーバーヘッドが発生してしまい、非効率です。そこで処理するデータはできるだけまとめて処理するようにしました。この処理により処理時間が50%削減できました。
BERTにデータを入力する際には、入力する系列の長さを揃える必要があり、短い系列にはダミーのトークンを足して、長さを一定にするPaddingという処理を行います。多くの場合、データの中で最長のものか、ある決められた長さに揃えます。しかしながら十分短い系列は、Paddingをすると本来の処理とは本質的には関係のないダミーのトークンが大部分を占めてしまうため、処理が非効率になってしまいます。そこでデータを長さが短い順に並び替えてから、バッチ化することにしました。この処理により、最初の方の短い系列のバッチは短い長さで揃えることができるので、Paddingによって挿入されるダミーのトークンの数を減らすことができます。この処理により、さらに処理時間が46%削減できました。
まとめ
Stockmarkでは日々、膨大な数のニュース記事に対してBERTの推論処理を行なっており、そのための強力な処理基盤が必要でした。そこで、Google Cloud PlattformでCloud TPUを用いたBERT推論のための基盤インフラを開発し、より効率的にデータ処理をすることが可能になりました。
機械学習システムを開発する際には、機械学習のアルゴリズムの特性に応じたインフラ設計が、最適なパフォーマンス得るために重要です。そのためには、インフラ技術と機械学習技術のそれぞれを深く理解し、それをうまく組み合わせることが必要となってきます。このようなインフラと機械学習のコラボレーションは今後ますます重要になってくると考えられ、Stockmarkでは今後も引き続き取り組んでいきたいと思います。
現在、Stockmarkではインフラや機械学習のエンジニアを募集しています!興味のある方は是非応募してください!
