Astrategyを支える技術: gRPC, Elasticsearch, Cloud TPU, Fargate... SaaS型AIサービスの内側の世界
ストックマークでは、法人ユーザー向けの「Astrategy」というウェブサービスを開発、提供しています。 本エントリでは、Astrategyで使われている技術やシステム構成をご紹介したいと思います。
Astrategyとは

Astrategyとは、AIがウェブニュースを解析してあらゆる市場の動向やトレンド、有力企業の経済活動を可視化し、ユーザーが市場調査や市場分析レポート作成を行うことができるウェブサービスです。
国内外約3万メディアから配信された約5000万件のビジネスニュースから、企業情報、言及されているニューストピック、業界や地域属性を抽出して分析に利用します。 抽出には汎用言語モデルBERTを用いており、その処理はCloud TPU上で動く重たい処理であるため、事前に全てのニュースデータに対して抽出処理をかけた状態で検索サーバーに登録しています。
ユーザーがAstrategyにアクセスし、欲しい記事の条件を入力すると、検索サーバーからその条件に合う記事を一度に取得し、そこにどのようなテーマが含まれているか、どのようなプレイヤー(企業、団体など)が存在するかなどを複数の切り口でインタラクティブに可視化します(図1)。 さらに、検索・分析の過程を保存する「ワークシート」と呼ばれる機能により、検索から分析の試行錯誤や定点観測をサポートしています。

高速なデータ構造化とリアルタイム分析を行うアーキテクチャ
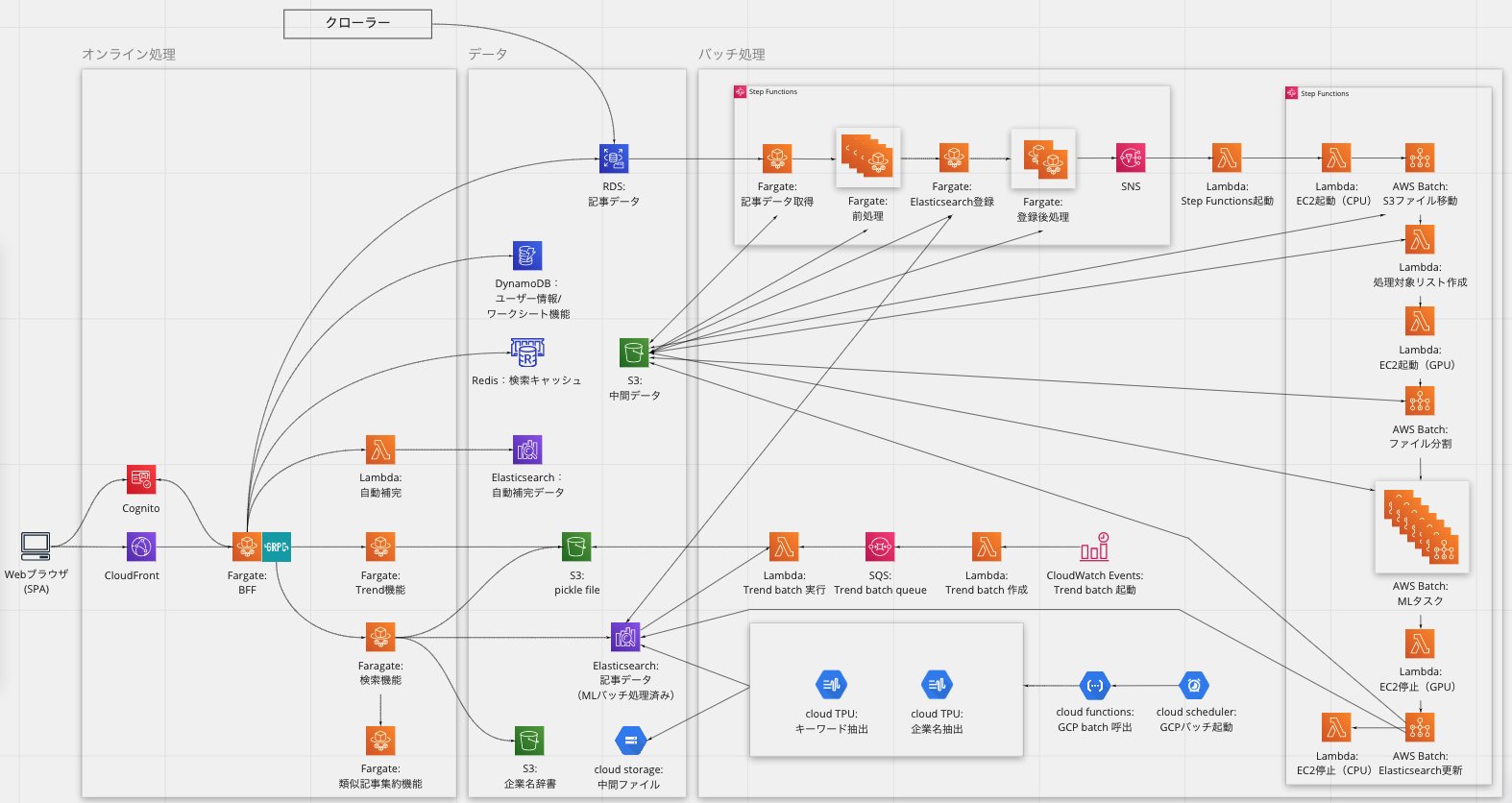
アーキテクチャの全体像は図2のようになっており、AWSとGCPを利用しています。
記事検索機能にはElasticsearchを用いており、そこにアクセスする部分のほとんどがPythonで書かれたマイクロサービス(AWS Fargate)となっています。 フロントエンドと各マイクロサービスとの間にはRailsをAPIサーバとして配置し、BFF(Backend for Frontend)のような扱いで利用しています。 それによって、各マイクロサービスとRailsはgRPCによって高速に通信しつつ、フロントエンド向けにデータを加工して返しています。 もう一台あるElasticsearchは、検索キーワード等の自動補完用です。
マイクロサービス(Fargate)からアクセスされているS3は、オンライン処理に利用される辞書データなどが入っており、Fargateの起動時にアクセスされそのFargateのメモリにロードされます。
ワークシート機能はAWSのDynamoDBを使って実現しています。 これによってフロントエンド主導でデータ構造を決めることができるため、高速な仮説検証と機能追加・改善が可能となっています。 それ以外のデータはMySQLに保存されており、オーソドックスにRailsのActive Recordから利用しています。
クローラーがその日に取得した数万件の記事は、記事検索に利用するElasticsearchにバッチ処理で登録します。 バッチ処理はAWSとGCPによるマルチクラウド構成となっています。 数万件に及ぶ大量の記事を時間内に処理するため、まずAWSでは、Cloudwatch Eventで定時起動したFargateやAWS BatchをStep Functionsで制御してGPUインスタンスを並列稼働させてElasticsearchへ登録しています。 さらに、企業名抽出、キーワード抽出など特段時間のかかる処理はGCPのCompute EngineとCloud TPUで個別に処理しています。
また、Lambdaで構成したバッチ処理を別時間帯に起動するなど、提供する形式に合わせてバッチ処理を分割して記事配信時間までに処理が完了することを担保しています。
フロントエンドの構成
フロントエンドは、スピーディな検索体験を提供するため、いわゆるSPA(Single Page Application)として構築されています。 フレームワークとしてVue.jsを採用し、コンポーネントは全てSFC (Single File Component) で構成しています。 scriptにはJavaScriptは使わずTypeScriptのみを用い、型のある開発を行っています。 CSSには、import機能や変数、ネスト機能などの機能の恩恵を受けるためにSassを使用しています。
Astrategyの特徴として、一度に大きいデータをバックエンドから受け取り、それらをインタラクティブに可視化することが重要な要件であることがあげられます。 そのため、データ可視化部分の信頼性を担保するテスタビリティの高い設計と、大量のデータを扱うためにパフォーマンスを重視した実装を指向するようにしています。 具体的には、例えば以下のような取り組みを続けています。
- テスタビリティを上げる取り組み
- 純粋な関数で表現できるデータの変換部分をコンポーネントから切り離す
- 状態を持つ部分(特に上記「ワークシート」を実現する部分)はVuex or Provide/Injectされたモデルに集約する
- パフォーマンス向上に繋がる取り組み
- (特にVue 2では)Vueのリアクティブな変数は性能面の課題が大きいため、巨大なオブジェクトや配列はコンポーネントに渡す前に処理したり、リアクティブな変数に変換させないように設定する
- 大量に項目があるリストや表については、画面内に描画するコンポーネントのみDOMを生成するようにする
- DOMの階層が深くなったり、レイアウト用のDOMが増え過ぎないように、CSSのGrid/Flexboxを活用する
これらのほか、PrettierやESLintを用いたコード品質の向上にも取り組みました。 以上の取り組みから、例えば図3のように滑らかな操作が可能となり、 ユーザーからUIの重さに起因する不満が挙がることはほぼなくなってきました。 さらに、フロントエンドでのより複雑な分析や可視化にも取り組めるようになってきています。
またデザイン面では、ストックマーク社内でdonguriと名付けられた共通のデザインシステムを運用しており、Astrategyにも適用しています。 これによって、他プロダクトとのUIの一貫性を保てるほか、開発効率の向上にも繋がっています。 ユーザーの皆様からもUIの使い勝手についても良いフィードバックをいただくことが多くなっています。
そのほか、WebAssemblyやgRPC-Webなどのさらなる高速化に寄与するであろう技術の検証も進めており、マッチするユースケースがあればプロダクトへ導入しようと考えています。
検索結果に対するテーマの抽出
Astrategyでは分析を行う軸として「テーマ」と「企業」を用いています。 ここではテーマの抽出について紹介します。
ユーザーが「自動運転」について直近1年間のニュース記事を検索した場合にヒットした記事群からテーマを自動抽出した結果が、図4の赤枠部分になります。 「実証実験」などがテーマとして抽出されており、テーマ右の数字は該当テーマに分類された記事数を表しています。
また、テーマに属する記事を企業名毎に分類することも行っています。

以前のブログ でも紹介したとおり、Astrategyではバッチ処理を用いることでニュース記事を構造化しています。 実はこの処理のなかで、記事内の特徴的なフレーズ抽出も同時に行っています。 オンライン処理では、Elasticsearchの検索でヒットした記事群からこのフレーズを集約し、 TF-IDF ベースの方法でランキング付けし抽出することで、テーマを作成しています。
また、似たようなテーマが乱立すると検索結果の見通しが悪くなるため、コサイン類似度などを用いて集約を行い、図5のようなテーマを図6のようにまとめています。


ランキング検索の手法には、動的ランキングによる方法等もあります[1] が、今回の処理では採用していません。 テーマ抽出においては、検索クエリはあくまでテーマ抽出を行う記事群を確定させるためのものとして使用し(この記事群を取得するための検索には、論理検索を用いています)、確定された記事群に出現するフレーズのランキング付けに関して、TF-IDFベースの方法を用いたということになります。
抽出されるテーマは、検索の結果ごと変化する必要があります。 例えば、「自動運転」と「医療」の検索ではテーマは変わるべきですし、同じ「医療」の検索であっても、2019年の1年間と直近1年間で抽出されるテーマは変わるべきです。 「医療」であれば、直近1年間では新型コロナウイルスに関するテーマが現れてきてもおかしくない一方、「自動運転」で調査したい場合には、新型コロナウイルス関連フレーズが例えある程度現れていたとしても、テーマとして採用するのはふさわしくないのでなるべく抑制をする必要があります。
バッチ処理で事前にフレーズ抽出をしたうえで、記事群が動的に決まる部分のランキング付けなどはオンライン側で処理も行うことで、図7、図8のように柔軟なテーマ抽出を実現しています。


検索ワードと企業名のサジェスト
Astrategyにおいて、ユーザがタイピングを行う箇所は、「検索結果に対するテーマの抽出」の章で紹介しましたテーマ抽出機能における「検索キーワード入力」と、企業ごとの比較を行う画面での「企業名入力」が該当します。 この2つのタスクおいて、以下の図9、図10にあるように、自動補完によるキーワードサジェストを行っています。
企業名補完については、入力確定後に、Stockmarkでメンテナンスしている企業名辞書による名寄せが行われます。 これによって企業名の表記ゆれが吸収され、例えば、企業名で比較をする際に、「ストックマーク」と「Stockmark」が重複して表示されることを防いでいます。
検索結果に対するテーマの抽出の章でも述べたように、Astrategyではバッチ処理によって、フレーズの抽出や企業名の抽出を行っています。
それらのデータと、Elasticsearch の機能を用いることで比較的簡単にサジェスト機能を作ることができました。
日本語に関しては、サジェスト機能の利用に関して留意する点などがあり、Elastic社のテックブログにまとまった情報があります。 ただし、文字の種類(かなカナ漢字等)にセンシティブでよい かつ、前方一致のみのサジェストでよければ、通常の「Suggesters」でも十分機能することがわかったため、Astrategyでは、MVPとしては設定が楽な後者を採用しました。
MLバッチ処理の最適化
先日、弊社のMLOpsへの取り組みをBERTを使ったMLバッチ処理実サービスのアーキテクチャとMLOpsの取り組みにて紹介しました。
Step FunctionsとAWS Batchを活用して実行されるMLタスクごとにリソースの最適化を行っていましたが、TPU VS GPU(日本語版)で紹介した結果から、いくつかのMLタスクをCloud TPUへ移行してマルチクラウド化しています。

マルチクラウド化以前、MLタスクはAWS BatchとLambdaをStep Functionsで制御して実行していました。 これは、AWS BatchにてMLタスクを実行する際にGPUインスタンス数が安定せずに処理遅延が発生する問題を解決するため、事前にLambdaから常時起動するGPUインスタンス数を変更しようと考えた構成です。 この構成にしたことで、GPUインスタンスが数台しか起動せずに並列実行できなかったり、MLタスクが残っている状態でもGPUインスタンスが停止したりすることがなくなり、MLタスクを安定して並列実行できた反面、処理時間の長いMLタスクに依存して複数起動したGPUインスタンスが全て起動したままになるという課題がありました。
マルチクラウド化に伴い、処理に時間がかかっていた企業名抽出とキーワード抽出を優先的にCloud TPUへ移行し、並列実行するMLタスクの処理時間を平準化したことで、GPUインスタンスの稼働時間を半分ほどに減らすことが可能となりました。 同時に、バッチ処理構成の見直しやGPUインスタンス数の調整、CPUインスタンスを含めたリソース再配分を行ったことで、年間$20,000ほどのコストを削減しています。
終わりに
いかがでしたでしょうか。 Astrategyは2019年12月にローンチ後、大手コンサルティングファームや事業会社など十数社のお客様に導入いただき、PMFに向けて急速にグロースしているプロダクトです。 一緒にプロダクトを成長させられる開発メンバーを募集中ですので、興味のある方はWantedlyをぜひご覧ください!




